

? 目标检测有非常广泛的应用, 例如:在安防监控、手机支付中的人脸检测;在智慧交通,自动驾驶中的车辆检测;在智慧商超,无人结账中的商品检测;在工业领域中的钢材、轨道表面缺陷检测。
? 目标检测关注的是图片中特定目标物体的位置。一个检测任务包含两个子任务,其一是输出目标的类别信息,属于分类任务;其二是输出目标的具体位置信息,属于定位任务。
? 早期,传统目标检测算法还没有使用深度学习,一般分为三个阶段:
- 区域选取:采用滑动窗口(Sliding Windows)算法(可以想象一个窗口在图像从左到右,从上到下,框出图像内容),选取图像中可能出现物体的位置,这种算法会存在大量冗余框,并且计算复杂度高。
- 特征提取:通过手工设计的特征提取器(如SIFT和HOG等)进行特征提取。
- 特征分类:使用分类器(如SVM)对上一步提取的特征进行分类。
2014年的R-CNN(Regions with CNN features)使用深度学习实现目标检测,从此拉开了深度学习做目标检测的序幕。并且随着深度学习的方法快速发展,基于深度学习的目标检测,其检测效果好,逐渐成为主流。
基于深度学习的目标检测大致可以分为。
-
目标检测的一阶段模型是指没有独立地提取候选区域(Region Proposal),直接输入图像得到图中存在的物体类别和相应的位置信息。典型的一阶段模型有SSD(Single Shot multibox-Detector)、YOLO(You only Look Once)系列模型等。
-
二阶段模型是有独立地候选区域选取,要先对输入图像筛选出可能存在物体的候选区域,然后判断候选区域中是否存在目标,如果存在输出目标类别和位置信息。经典的二阶段模型有R-CNN、Fast R-CNN、Faster R-CNN。
-
如下图,两阶段的检测算法精度会比一阶段检测算法高,而检测速度确不如一阶段的检测算法,二阶段检测算法适合对精度要求高的业务,一阶段检测算法适合对实时性要求高的业务。

YOLO()是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。
论文下载地址: https://arxiv.org/pdf/1506.02640.pdf
第一个版本的YOLO的特征提取网络有24个卷积层和2个全连接层。网络结构如下图。

- 可以看出,这个网络中主要采用了1x1卷积后跟着3x3卷积的方式。
- 特征提取网络采用了前20个卷积层,加一个avg-pooling层和一个全连接层,对ImageNet2012进行分类,top-5正确率为88%,输入分辨率为224x224。
- 检测时,将输入分辨率改为448x448,因为网络结构是全卷积的,所以输入分辨率可以改变,整个网络输出为7x7x30维的tensor。
- YOLO网络借鉴了GoogLeNet分类网络结构,有24个卷积层+2个全连接层。
图片参数中的s-2指的是步长为2,这里要注意以下三点:- 在ImageNet中预训练网络时,使用的输入是224 * 224,用于检测任务时,输入大小改为448 * 448,这是通过调整第一个卷积层的步长来实现的;
- 网络使用了很多1*1的卷积层来进行特征降维;
- 最后一个卷积层的输出为(7, 7, 1024),经过flatten后紧跟两个全连接层,形成一个线性回归,最后一个全连接层又被reshape成(7, 7, 30),形成对2个box坐标及20个物体类别的预测(PASCAL VOC)。
LeakyReLU:

在YOLO算法中把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。

算法首先把(也可说是输入图像,因为输入图像的网格区域与特征图的网格区域有对应关系)划分成S×S的栅格,然后对每个栅格(grid cell)都预测B个bounding boxes,每个bounding box都包含5个预测值:x,y,w,h和confidence。
-
就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;
-
进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)。
-
代表了和两重信息:
除了确定是否包含物体,还需确定每一个栅格(grid cell)预测的物体类别?对于有C个类别的数据集,会对每个类别预测出类别概率。

。


一个网络如何学习预测物体类别和物体位置,这就要看损失函数了。



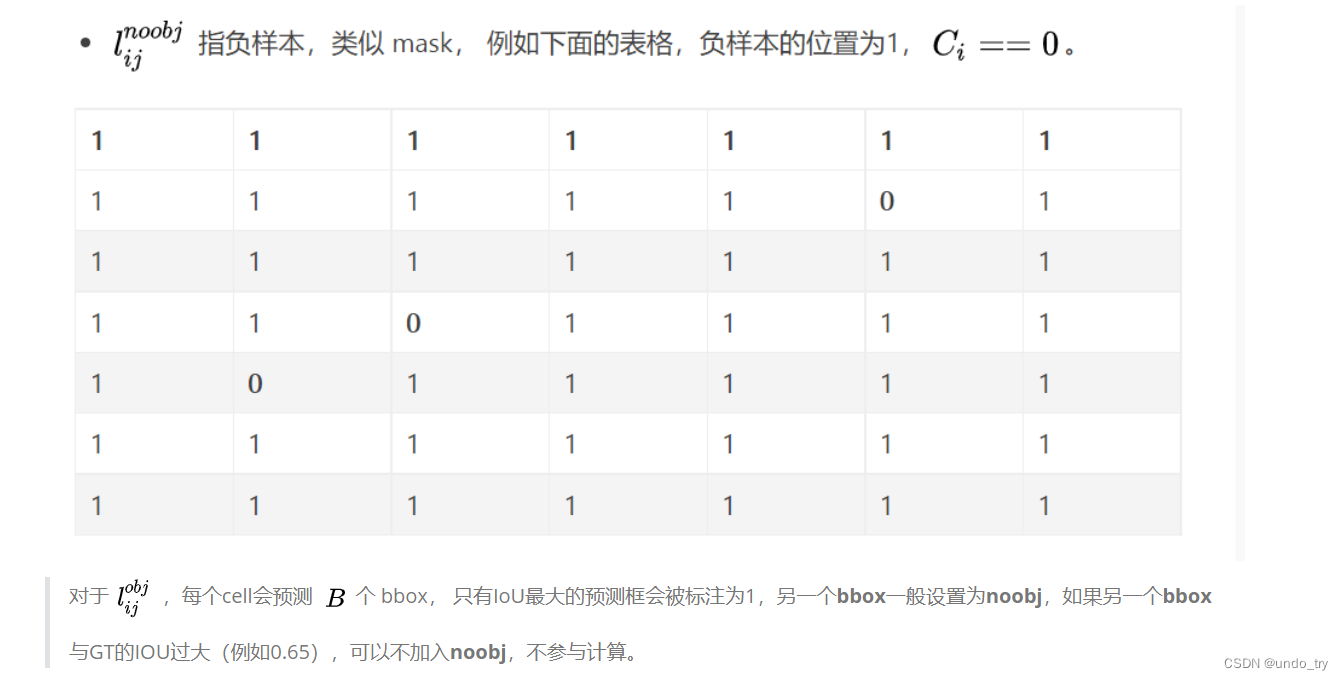
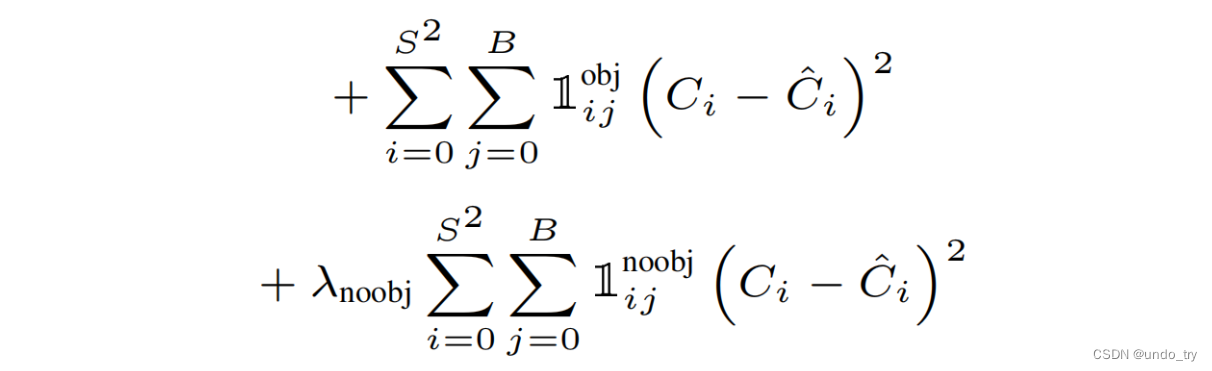


每个cell最终只预测一个物体边框,依据预测出B个bbox与标注框计算IOU,选取最大的IOU的物体边框。
loss函数的代码实现
优点: 速度快,简单
缺点:
- 每个栅格(grid cell)只预测一个类别,对拥挤的物体检测不太友好
- 对小物体检测不好,长宽比单一
- 没有Batch Normalize
链接:https://pan.baidu.com/s/1tnTpr6xFY6mK8q2jfhZBZQ
提取码:
链接:https://pan.baidu.com/s/1-0U9w_XBGzYpzP4ND25blQ
提取码:
链接:https://pan.baidu.com/s/1cJPer12vhuubqDeLcRQoPQ
提取码:
。
第一个网盘连接中,有三个压缩包。将、测试集、训练集/验证集分别下载到本地。

分别解压这个三个压缩包到【注意:解压选项为当前文件夹】。解压后,如图所示。
其中,中的文件是 development kit code and documentation ,即一些开发工具包代码和文档,如下图所示。有一些MATLAB代码,就是用这些代码处理的这个数据集,还有一个, 是一个比较详细的说明书。

解压后的文件夹中有以下五个部分,如下图所示。

Annotations
??这个文件夹里都是文件,,如下图所示。每个文件里面保存的是每张图像的标注信息,训练时要用的label信息其实就来源于此文件夹。

例如文件如下所示:
ImageSets
??这个文件夹里面是图像划分的集合 ,打开之后有3个文件夹: 、 、 ,如下图所示,这3个文件夹对应的是 VOC challenge 3类不同的任务。

VOC challenge的Main task,其实是classification和detection,所以在文件夹中,包含的就是这两个任务要用到的图像集合,如下图所示。
共有84个文件
-
其中4个文件为训练集、验证集、训练集和验证集汇总、测试集,这4个文件里面保存的是图像的ID号;
-
还有20类目标,每个类别有该类的、、、这4个文本,共80个文件。这80个文件中每一行的图像ID后面还跟了一个数字,要么是-1, 要么是1,有时候也可能会出现0,意义为:-1表示当前图像中,没有该类物体;1表示当前图像中有该类物体;0表示当前图像中,该类物体只露出了一部分。

还有两个taster tasks :Layout和Segmentation,这两个任务也有各自需要用到的图像,就分别存于和两个文件夹中,如下图所示,分别有4个文件:训练集、验证集、训练集和验证集汇总、测试集。

JPEGImages
??这个文件夹里面保存的是数据的原始图片,打开之后全是图片,如下图所示,共有9963张图像。

SegmentationClass
??这个文件夹里面保存的是专门针对Segmentation任务做的图像,里面存放的是Segmentation任务的label信息。

SegmentationObject
??这个任务叫做Instance Segmentation(样例分割),就同一图像中的同一类别的不同个体要分别标出来,也是单独给的label信息,因为每个像素点要有一个label信息。


数据集划分流程:
- 获取’/VOC2007/Annotations’ 下以’.xml’结尾的文件名。
- 从总的样本中按照数据集比例抽取样本,得到每个数据集的索引。
- 不同数据集的存储地址。
- 遍历样本,根据抽取的样本索引放入不同的数据集中。
- 关闭文件。
运行代码,生成4个文件,

把图片信息和xml信息放在一起。
- 遍历每个数据集获取数据集图片名。生成解析文件,用来存储图片地址和框的信息。
- 遍历每张图片,解析文件写入图片地址,打开xml文件,读入类别信息和框的信息。
- 关闭解析文件
运行后,生成3个文件

此文件主要任务就是根据txt文件内的信息制作ground truth,并且还会进行一定的数据增强。最终输出一个7×7×30的张量。
对图片数据增强,增加样本,提高模型的泛化能力。
- 首先把图片名称、框、类别信息分别存储。
- 生成迭代器,对每个图片进行数据增强。翻转、缩放、模糊、随机变换亮度、随机变换色度、随机变换饱和度、随机平移、随机剪切。
- 编码。对于增强后的图片,根据图片宽高,获取框在图片的相对位置、去均值、统一图片尺寸、编码。编码的关键在于找到真实框在特征图上的相对位置。先把真实框左上角和右下角坐标转换为中心点和宽高,中心点坐标x特征图宽高后,向下取整在-1就得到真实框在特征图上的位置ij。中心点坐标x特征图宽高-ij得到真实偏移。根据ij输入偏移、宽高、类别信息。
论文中的主干模型是由24层卷积和两个全联接组成。下面代码中训练主要包括backbone(ResNet、VGG)、LOSS、代入数据训练模型。
2.3.1.1 利用ResNet作为主干网络
ResNet主要分为三部分。首先通过卷积和池化进行两次步长为2的下采样,然后通过残差模块layer1~layer5扩展通道数和三次步长为2的下采样,最后一次卷积、批归一化、激活得到特征图[7,7,30]。
我们使用下面的resnet50网络,按照YOLOV1的要求输入图像的尺寸为448×448×3,要求输出7×7×30的张量,而ResNet50可以输入224任意倍数的彩色三通道图片(当然也包括448),所以与YOLOV1算法契合度较高。若输入448×448×3的图片经过ResNet50会得到2048×14×14的张量,所以还需要进行后续处理。
2.3.1.2 利用VGG作为主干网络
VGG 模型分为两大部分,一部分用卷积、池化提取特征,然后通过两次全连接得到特征。
2.3.2.1 损失函数
YOLOV1计算损失的特殊性:用MSE计算损失,对框回归的宽高先开方在进行MSE,解决大小物体损失差异过大的问题。对回归和前景分类赋予不同的权重,解决正负样本不均衡问题。
计算损失时,输入的是真实框target_tensor、和解码后的预测框pred_tensor[batch_size,7,7,30].
(1)计算损失流程:
- 根据真实框的置信度对target_tensor和pred_tensor取出没有真实框的样本sample_nobj[-1,30],在取出样本的第5列和第10列,用mse计算负样本的损失noobj_loss。
- 根据真实框的置信度对target_tensor和pred_tensor取出没有真实框的样本sample_obj[-1,30]。对取出的样本分别在提取target_tensor和pred_tensor的框和物体类别,计算类别损失。
- 根据sample_obj,计算预测框和真实框的IuO,根据IuO选出与真实框匹配的样本,计算框的回归损失和正样本的损失。预测正样本的真实值用IuO计算。
- 对各种损失加权以平衡正负样本不平衡
2.3.2.2 IoU的计算
I. 计算框相交部分的左上角和右下角坐标lt,rd。
II. 计算交集面积inter和相交框的各自面积area1、area2。
III.根据以上步骤计算交并比iou。
训练流程:
- 导入库
- 设置超参数
- 模型
- 导入模型参数
- 损失函数
- 设置优化器
- 导入数据
- 训练

(1)对于类别1, 从概率最大的bbox F开始,分别判断A、B、C、D、E与F的IOU是否大于设定的阈值。
(2) 假设B、D与F的重叠度超过阈值,那么就扔掉B、D(将其置信度置0),然后保留F。
(3) 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
(4) 重复这个过程,找到此类别所有被保留下来的矩形框。
(5) 对于类别2,类别3等等…都要重复以上4个步骤。
-
首先需要导入模型以及参数,并且设置好有关NMS的两个参数:。然后就可以开始预测了。首先需要通过opencv读取图片并且将其resize为448?448的RGB图像,将其进行均值处理后输入神经网络得到7?7?30的张量。
-
然后运行 decode 方法:因为一个grid ceil只预测一个物体,而一个grid ceil生成两个bbox。这里对grid ceil进行以下操作。
- 1、选择置信度较高的bbox。
- 2、选择20种类别概率中的最大者作为这个grid ceil预测的类别。
- 3、置信度乘以物体类别概率作为物体最终的概率。
- 最终输入一个7?7?6的张量,7?7代表grid ceil。6 = bbox的4个坐标信息+类别概率+类别代号
-
最后运行 NMS 方法对bbox进行筛选:因为bbox的4个坐标信息为(xc,yc,w,h)需要将其转化为(x,y,w,h)后才能进行非极大值抑制处理。

